Abstract
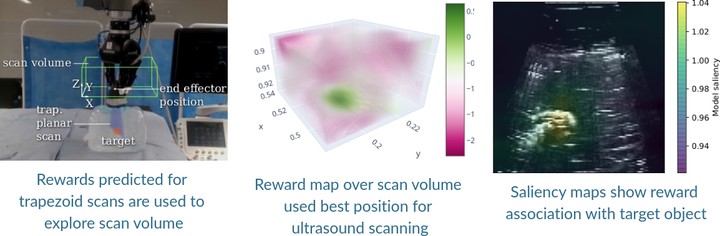
This paper addresses a common class of problems where a robot learns to perform a discovery task based on example solutions, or human demonstrations. For example consider the problem of ultrasound scanning, where the demonstration requires that an expert adaptively searches for a satisfactory view of internal organs, vessels or tissue and potential anomalies while maintaining optimal contact between the probe and surface tissue. Such problems are currently solved by inferring notional rewards that, when optimised for, result in a plan that mimics demonstrations. A pivotal assumption, that plans with higher reward should be exponentially more likely, leads to the de facto approach for reward inference in robotics. While this approach of maximum entropy inverse reinforcement learning leads to a general and elegant formulation, it struggles to cope with frequently encountered sub-optimal demonstrations. In this paper, we propose an alternative approach to cope with the class of problems where sub-optimal demonstrations occur frequently. We hypothesise that, in tasks which require discovery, successive states of any demonstration are progressively more likely to be associated with a higher reward. We formalise this temporal ranking approach and show that it improves upon maximum-entropy approaches to perform reward inference for autonomous ultrasound scanning, a novel application of learning from demonstration in medical imaging.